About the Meeting
The Annual Meeting of the International Society for Data Science and Analytics (ISDSA) serves as a global platform for researchers and practitioners in the dynamic field of data science and analytics to exchange ideas and present cutting-edge research. This inclusive event welcomes participants with an interest in data science, data analytics, and broader quantitative research.
The 2025 Annual Meeting of ISDSA is scheduled to be held in Washington, DC, focusing on the theme "Data Science and Machine Learning."
Submit an Abstract by Feb 15, 2025
We invite you to contribute to the intellectual discourse by submitting abstracts for the 2025 meeting. The theme, "Data Science and Machine Learning," encompasses theoretical and methodological papers, applications, case studies, and tutorials. Abstract submissions are open until Feb 15, 2025. Early submissions are encouraged. Presentation formats include regular 30-minute paper sessions and concise 10-minute speed presentations.
Workshops
Four online workshops will be offered during this year's meeting, two on July 11 and two on July 14. More information will be available soon.
1. Structural Equation Modeling using OpenMx by Prof. Steve Boker of University of Virginia
2. Analytic Methods for Process Data in Large-Scale Assessments by Prof. Qiwei He of Georgetown University and Prof. Susu Zhang of University of Illinois Urbana-Champaign
3. Structural Equation Modeling with Text Data by Prof. Zhiyong Zhang of University of Notre Dame
4. Introduction to Graph Machine Learning: Methods and Applications by Prof. Dundong Li of University of Virginia
Awards
A paper will be selected for the best paper award. The award comes with a $500 check and a certificate.
Share the meeting
You can share the meeting information with a colleague by inputting their email and name below.
Workshops
Four workshops will be available. You will get a certificate of achievement for each workshop after completing it. Each workshop is 3-hour long and taught online through Zoom.
Workshop: Introduction to Graph Machine Learning: Methods and Applications
Time: TBA
Location: Virtual on Zoom (Register to get the link)
Graph-structured data is central to many real-world problems, encompassing domains such as recommender systems, social network analysis, and computational biology. This workshop offers a comprehensive introduction to graph machine learning, covering foundational concepts and state-of-the-art techniques. Participants will learn about graph representation learning and graph neural networks, with a focus on practical applications in the aforementioned areas. Through lectures and discussions, attendees will gain insights into how graph machine learning is transforming diverse fields. This workshop is designed for researchers, practitioners, and students seeking to understand and apply graph-based methodologies to solve complex challenges.
-

Jundong Li -- University of Virginia
Jundong Li is an Assistant Professor at the University of Virginia with appointments in Department of Electrical and Computer Engineering, Department of Computer Science, and School of Data Science. Prior to joining UVA, he received his Ph.D. degree in Computer Science at Arizona State University in 2019 under the supervision of Dr. Huan Liu, M.Sc. degree in Computer Science at University of Alberta in 2014, and B.Eng. degree in Software Engineering at Zhejiang University in 2012. His research interests are generally in data mining and machine learning, with a particular focus on graph machine learning, trustworthy/safe machine learning, and more recently on large language models. He has published over 150 papers in high-impact venues (including KDD, WWW, WSDM, NeurIPS, ICML, ICLR, IJCAI, AAAI, ACL, EMNLP, NAACL, SIGIR, CIKM, ICDM, SDM, ECML-PKDD, CSUR, TPAMI, TKDE, TKDD, TIST, etc), with over 14,000 citation count. He has won several prestigious awards, including SIGKDD Rising Star Award (2024), PAKDD Early Career Research Award (2023), PAKDD Best Paper Award (2024), NSF CAREER Award (2022), SIGKDD Best Research Paper Award (2022), JP Morgan Chase Faculty Research Award (2021 & 2022), and Cisco Faculty Research Award (2021), among others. His group's research is generously supported by NSF (CAREER, III, SaTC, SAI, S&CC), DOE, ONR, Commonwealth Cyber Initiative, Jefferson Lab, JP Morgan, Cisco, Netflix, and Snap.
Workshop: Analytic Methods for Process Data in Large-Scale Assessments
Time: TBA
Location: Virtual on Zoom (Register to get the link)
The use of computers as a delivery platform not only enables the development of innovative item types but also facilitates the collection of a broader range of records in log files throughout human-machine interactions. These granular records, often referred to as process data, are typically stored as an ordered sequence of multi-type, time-stamped events. This rich source of data supports the exploration and identification of informative features from problem-solving processes beyond response data. They are used to investigate when and how respondents engage in solving interactive tasks (Goldhammer et al., 2014; He et al., 2021, 2023), to identify test-taking strategies across population subgroups, such as age, gender, and educational attainment (Eichmann et al., 2020; Liao et al., 2019), and to shape future test and item design (Zhang et al., 2023).
This training session introduces the fundamental structure and analytic methods of process data, aiming to support the incorporation of response process information in large-scale assessments. The training will combine theoretical instructions on methodologies to analyze process data through sequence-based and feature-based approaches, along with programming code demonstrations, and case study illustrations using process data in Program for the International Assessment of Adult Competencies (PIAAC) and National Assessment of Educational Progress (NAEP).
This training session will be conducted in two sections, focusing on four subtopics: (1) creating and selecting informative features from process data in large-scale assessments, (2) extracting and selecting gram-based features from clickstream sequences, (3) computing sequence distance to identify pairwise sequence similarity and conduct sequence clustering, and (4) identifying and interpreting meaningful patterns from process data. Section 1 will provide an overview of process data structure, preprocessing, and methods for extracting information from process data through sequence mining techniques. Section 2 will introduce feature-based process data analysis, covering how to create and select process variables and integrate content experts’ insights into these variables. Each section will be supported by case studies as illustrations.
This training session will enable participants to understand process data structure, gain basic knowledge about sequence- and feature-based methods for analyzing process data, and how to choose appropriate methods for their own research. All program codes will be included in the training package for participants’ self-learning and further programming needs.
-

Qiwei He -- Georgetown University
Dr. Qiwei He is Associate Professor in the Data Science and Analytics Program, and Founder and Director of the AI-Measurement and Data Science Lab at Georgetown University. Her research focuses on advancing methodologies in sequence mining, text mining, psychometric modeling, and machine learning on new data sources such as process data and textual data collected in digital-based assessments in education, psychology, psychiatry, and public health. She was an OECD Thomas Alexander Research Fellow and recipient of NCME Annual Award (2023), Jason Millman Award (2019), and Alicia Cascallar Award (2017) for her contribution to developing and applying new methods in process data analysis.
-

Susu Zhang -- University of Illinois Urbana-Champaign
Dr. Susu Zhang is an Assistant Professor of Psychology and Statistics at the University of Illinois Urbana-Champaign (UIUC). Her research involves latent variable modeling for testing and learning data, and the analysis of complex process data to inform educational measurement. She is the co-author of the R package ProcData for exploratory process data analysis and the recipient of NCME Alicia Cascallar Award (2022) for her outstanding work in integrating process data in psychometric models.
Workshop: Structural Equation Modeling with Text Data
Time: TBA
Location: Virtual on Zoom (Register to get the link)
Text data are increasingly abundant in social science research, yet they are often underutilized in analysis. In this workshop, I will demonstrate how to conduct structural equation modeling (SEM) using both quantitative and qualitative data. The session will begin with an overview of SEM, covering its fundamental concepts and applications. Next, I will explore various approaches to extracting insights from text data, including dictionary-based methods, AI-driven sentiment analysis, and word embeddings. Following this, I will discuss how to integrate text data with other data types within the SEM framework. To illustrate these methods, I will use teaching evaluation data as a case study. Finally, I will showcase how to use the R package TextSEM and the online application BigSEM, developed in my lab, to conduct SEM with text data. Participants will leave the workshop equipped with practical tools and techniques for harnessing the potential of text data in their research.
-

Johnny Zhang -- University of Notre Dame
Dr. Johnny Zhang is a professor in Quantitative Psychology at the University of Notre Dame. His research aims to develop better statistical methods and software in the areas of education, health, management and psychology. He has conducted research in the areas of Bayesian methods, Big data analysis, Structural equation modeling, Longitudinal data analysis, Mediation analysis, and Statistical computing and programming. His most recent research involves the development of new methods for social network and text analysis.
Registration
To register, click the link here. It will take you to our meeting registration and management website.
Meeting Registration
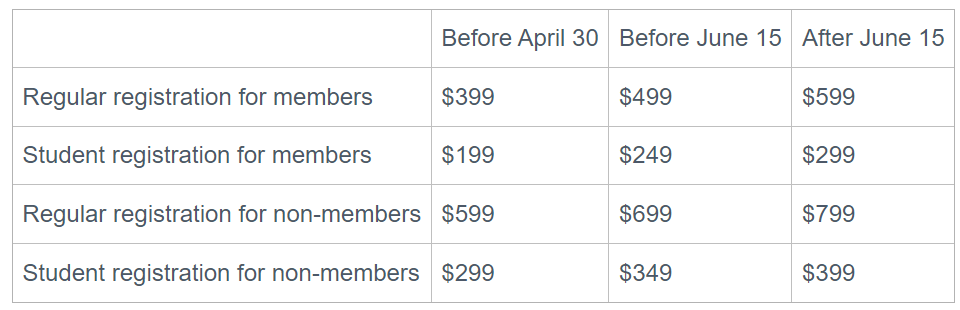
If you are not an ISDSA member, you can register to become a member now. New memberships are free through the end of 2025 with meeting registration. To have your 2025 membership fee waived, please email meeting@isdsa.org to confirm your attendance. Note that your membership ID is different from the ID used for the meeting website.
Workshop Registration
The price is for all four workshops.
Meeting participants: Free
Students: $25
All others: $50
For each workshop, we can only accommodate 100 participants. To register, please use our registration platform before July 1, 2025.
Refund Policy
For any reason that prevents you from attending the meeting or workshop, you can request a refund by contacting us. The refund amount depends on the time you make the request.
Before June 1: Refund full registration fee minus 5% of the processing fee (charged by the third party)
After June 1 & before June 25: Refund 80% of the full registration fee.
After June 25: no refund.
Hotel
The meeting is taking place at the Hilton Washington DC National Mall The Wharf. We have reserved a book of rooms at a reduced rate ($245 plus tax per night). To book the hotel, follow the link here. You can also directly book on Hilton's website using the group code "ISDSA".
Sponsors
The meeting is jointly supported by the International Society for Data Science and Analytics, the College of Management of National Taiwan Normal University, the Nanjing University of Posts and Telecommunications, and the University of Notre Dame.




Sponsoring Journals
Selected papers will be published free of charge in the Journal of Behavioral Data Science and the journal Computation after peer review.
Organizing Committee
-

Hawjeng Chiou
Distinguished Professor
National Taiwan Normal University -

Haiyan Liu
Assistant Professor
University of California, Merced -

Jiashan Tang
Professor
Nanjing University of Posts and Telecommunications -

Xin Tong (Chair)
Associate Professor
University of Virginia -

Manshu Yang
Assistant Professor
University of Rhode Island -

Ke-Hai Yuan
Professor
University of Notre Dame -
Zhiyong Zhang
Professor
University of Notre Dame
Contact information
Email: meeting@isdsa.org
Mail: P.O.Box 1471, ISDSA, Granger, IN 46530